
 from [MIT Media Lab](https://www.media.mit.edu/)](/assets/images/featured2-fdbaa2ecdf7b30e6e8ab8213f0d6e47d.jpeg)
The growth of video content is unprecedented. As of 2019, more than 720 thousand hours of videos are uploaded to YouTube every day, more than 1 billion of hours of video are watched daily only on this platform. In 2021, these numbers globally might be several times higher given the huge popularity of the services like TikTok and Instagram Stories. With such rapid growth of video volume, it is obvious that we desperately need systems that would enable us to index and search video data using queries of different types.
Content-Based Video Retrieval
The content-based video retrieval (CBVR) area studies these issues. According to Wikipedia, the concept of content-based video retrieval was introduced in 1993 by Iranian engineer Farshid Arman, Taiwanese computer scientist Arding Hsu, and computer scientist Ming-Yee Chiu. At that time, the first task defined within the CBVR context was detection of shots boundaries. Since then, the area has been developing rapidly.
For ordinary people, the main application of the advances in this field is comprised in the ability to search for videos using queries of different types, e.g., images, text descriptions, video and audio samples, etc. Not surprisingly that in the non-scientific world this area is better known as reverse video search. In the research community, the terms content-based video search (CBVS) and content-based video indexing and retrieval (CBVIR) are also widely used as synonyms.
Hu et al1. define (in a broad sense as multimedia) content-based video retrieval in the following way:
Multimedia information indexing and retrieval are required to describe, store, and organize multimedia information and to assist people in finding multimedia resources conveniently and quickly.
Although this definition is short and concise, the research area itself is enormous. Indeed, for instance one can search for a video providing a text description, other may supply an image or by video sample as a query. The text description may contain information about objects, named entities, actions, or events. Only these several examples already show that this field of study is huge and closely connected with other research areas such as content-based image retrieval, audio data analysis, machine learning, text processing, human-computer interaction, etc.
To provide a forum for ideas exchange and a unified testbed for findings evaluation in the CBVR field, in 2001 a separate track called Video Retrieval Evaluation, or TRECVID for short, was organized within the Text REtrieval Conference (TREC). Within this contest, the organizers specify different CBVR-related tasks and publish datasets and methodology to evaluate the advances of researchers. The aim of this contest is to provide an independent platform for scientific results evaluation. Since that time, the scientific advances in the CBVR area are closely connected with this contest and the public datasets released within this initiative. For instance, 90 peer-reviewed journal and conference papers, which make use of TRECVID resources, were published only in 2019.
TRECVID Tasks
Before starting working at Vertx, I have never thought that the CBVR area is that broad. There are so many methods to analyze, characterize, index, and search videos, that it is almost impossible to describe them all. Therefore, to show the immensity of the CBVR area, let us consider only several popular TRECVID tasks.
Shot Boundary Detection
As we have already mentioned, the concept of content-based video retrieval appeared due to shot boundary detection problem -- it was one of the first issues in this area. Not surprisingly that it is also appeared as one of the first tasks in the TRECVID contest in 2001. Indeed, before starting to describe a video you need to segment it at first. Naturally, every video is represented as a set of images (frames) changing each other rapidly so that a human eye does not spot the transitions and sees only smooth movements of objects on a screen.
Obviously, it is redundant to describe every frame because usually there is a very small difference between two consecutive frames. To reduce the redundancy, scientists working in this area usually deal with shots -- an image sequence that presents continuous action which is captured from a single operation of single camera2.
The goal of the shot boundary detection task is to identify the shots boundaries with their location and type (cut or gradual).
Shot is the smallest indexing unit, and usually more advanced tasks are formulated with respect to this segment type. For instance, the semantic indexing task would be formulated as finding shots (not frames) where a concept is present.
High-Level Feature Extraction
After a video is split into shots, then you need somehow to describe them. The High-Level Feature Extraction (or Semantic Indexing) task was created to evaluate the advances in tackling this problem.
The goal of the high-level feature extraction or semantic indexing task is to return for each concept a bounded list (e.g., with max of 2000 items) of shot IDs ranked according to their likeliness of containing the concept, given the test collection of videos, common shot boundaries, and concept definitions.
The searched concepts could include various things: concrete person (e.g., Obama or P!nk), animal (dog, cat) or thing (helicopter, computer); group of people (girls, men, baby, soldiers); actions (men shaking hands, people singing, airplane flying, rocket taking off); etc. For instance, within TRECVID 2008 the following concepts were asked to be identified (here I provide just some of them, see this document for the full list):
- Classroom: a school- or university-style classroom scene. One or more students must be visible. A teacher and teaching aids (e.g. blackboard) may or may not be visible.
- Bridge: a structure carrying a pathway or roadway over a depression or obstacle. Such structures over non-water bodies such as a highway overpass or a catwalk (e.g., as found over a factory or warehouse floor) are included.
- Airplane_flying: external view of a heavier than air, fixed-wing aircraft in flight -- gliders included. NOT balloons, helicopters, missiles, and rockets.
- Singing: one or more people singing -- singer(s) visible and audible, solo or accompanied, amateur or professional.
These concepts can be characterized using the Panofsky-Shatford mode/facet matrix3 (see Figure 1):
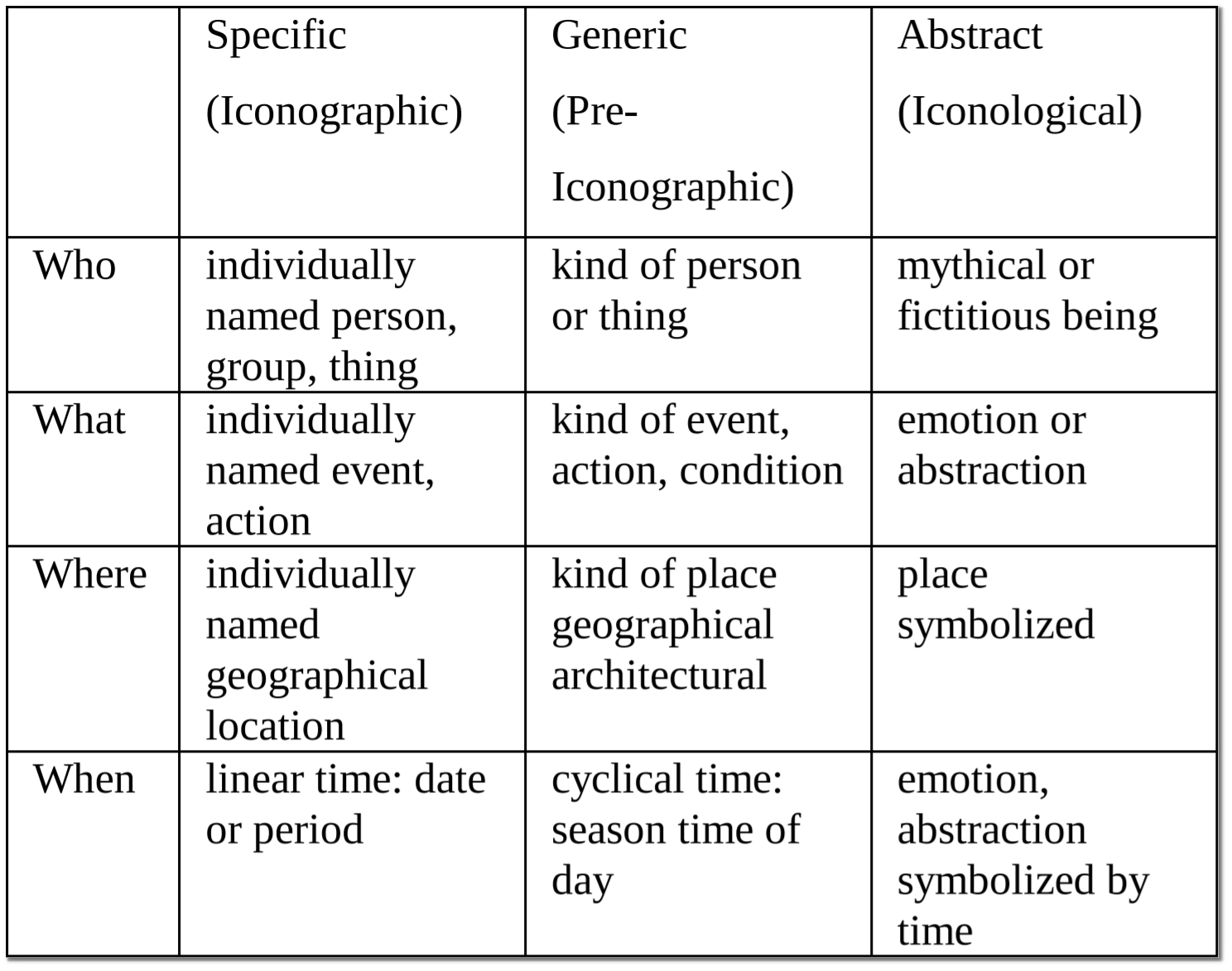 FIGURE 1: Panofsky-Shatford mode/facet matrix
FIGURE 1: Panofsky-Shatford mode/facet matrix
With the lapse of time, more advanced tasks have appeared at TRECVID targeting more specific problems within the same context. These tasks include concept localization (detect spatial and temporal localization of a concept on a video), multimedia event detection (identification of a complex event, e.g., flash mob), surveillance event detection (detection of events on videos captured with surveillance cameras), activities detection in extended video (detection of the same events captured with multiple cameras).
The development of the semantic indexing task is to provide a free textual description of videos. Recently, the TRECVID organizers have added video to text description task to the contest program in order to speed up the research in this area.
Ad-hoc Video Search
After concepts are localized in videos, the next step is to find video segments containing particular concept or group of them. For instance, a user may want to find shots: taken at night; of a person playing a piano; with Michael Jackson; of embracing people, etc. The TRECVID ad-hoc video search task aims at evaluating the advances in this area.
The goal of the ad-hoc video search task is to return a bounded list of shot IDs, which best satisfies the user need, given a user query and video collection with common shot boundaries.
Within this task, one needs somehow to map user queries and concepts detected on videos. It is a quite difficult task, therefore not surprisingly that this task appeared almost every year during the last 20 years.
Other TRECVID Tasks
Other popular TRECVID tasks include instance search (find a video of a person, place, or thing of interest, known or unknown, providing an instance, e.g., video or set of images, of the same concept), video summarization (create a video summary containing only important events), streaming multimedia knowledge base population (given streams of text, speech, images, video, and their associated metadata, produce a set of structured representations about events, sub-events or actions, entities, relations, locations, time, and sentiments). If you are interested in the topic, you can visit the contest web page and check each year competition details.
TRECVID and Vertx
You may ask why do I spend so much time in this article describing the TRECVID contest tasks? The answer is simple: one task run within this contest is closely connected to what we are doing in Vertx, and it is called as content-based copy detection.
The goal of content-based copy detection is to determine whether a given video (possibly, transformed) contains a segment of any reference video.
This is the topic that we explore in Vertx, and the results of our research constitute the foundation of the services we provide. At the first glance, it seems like an easy problem, however in reality, it is not as every aspect related to video analysis.
There are many issues that have to be addressed in this area. First, it is obvious that we cannot operate on raw video. Indeed, storing all videos in a library and comparing a given video with every clip from the database would require enormous storage and computational resources. Therefore, in Vertx we explore how to produce compressed but at the same time expressive representations of a video, which we call as fingerprints. The results of our research allow us to save storage and computational resources, to ensure the privacy of user-uploaded videos (i.e., we cannot restore a video from its fingerprint), and to identify reference videos almost in real-time.
Second, a given video may be transformed. For instance, a resolution can be reduced, or a video can be composed of several pieces. It can be even taken from a screen using a camera. In Vertx, we develop algorithms that are robust to these transformations. This allows our service to find a reference movie even from a screen-copied reproduction, or to identify a TV show using a sample recorded from a screen with a mobile phone.
Third, an audio track may not correspond to a video track. Indeed, the original audio track may be replaced, or if a video is taken using a camera, it may contain a background noise or other sounds. Therefore, in Vertx we index video and audio tracks separately. This allows us to detect dubbed videos or videos with an audio noise. As a side effect, our service is also able to identify popular songs in videos. This functionality enables us, e.g., to automatically detect soundtrack songs in a movie.
- W. Hu, N. Xie, L. Li, X. Zeng and S. Maybank. "A Survey on Visual Content-Based Video Indexing and Retrieval." IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), vol. 41, no. 6, pp. 797-819, Nov. 2011, doi: 10.1109/TSMCC.2011.2109710.↩
- Patel, B. V., and B. B. Meshram. "Content based video retrieval systems." arXiv preprint arXiv:1205.1641 (2012).↩
- Enser, P. G. B., and C. Sandom. "Retrieval of archival moving imagery: a step too far for CBIR." Proceedings from International workshop on Multimedia Content-based Information Retrieval (MMCBIR) France. 2001.↩